前回TF-Slim画像識別ライブラリを使って、転移学習を試してみました。その際使用したデータセットは、用意されていた花画像データセットを使用しましたが、自前で用意した画像も使える様にしたかったので、今回はTF-Slim画像識別ライブラリで使用できる形式のデータセットを作成するスクリプトを作ってみました。
環境
・TensorFlow r0.12
・TensorFlow-Slim image classification library
・自前で用意した画像は、imagesフォルダに下記の様に保存されているとします
images +- tulip00.jpg +- Lexus03.jpg +- … +- list.csv #ラベル一覧
ラベルデータを含んだCSVファイルは、[ファイル名,ラベル]というフォーマットで保存しておきます。
flower00.jpg, flower Lexus03.jpg, car …
データセットの作り方
元々TF-Slim画像識別ライブラリには、MNISTやCIFAR10といったデータセットを変換するプログラムが用意されているので、それらを参考にすれば作れそうです。
一通りソースコードを眺めてみると、どうやら下記データ項目を持ったTFRecordを作成すれば良いことがわかります。
datasets/dataset_utils.py
def image_to_tfexample(image_data, image_format, height, width, class_id):
return tf.train.Example(features=tf.train.Features(feature={
'image/encoded': bytes_feature(image_data),
'image/format': bytes_feature(image_format),
'image/class/label': int64_feature(class_id),
'image/height': int64_feature(height),
'image/width': int64_feature(width),
}))
ということで、画像ファイルパスから画像データを読み込み、TFRecordファイルに変換するプログラムの下記の様に作成してみました。
filepath_listsは、shape=[出力ファイル数, (1ファイル当たりの)画像数]の2次元配列になっています。label_listsも同じです。
def write_tfrecord(split_name, filepath_lists, label_lists):
jpeg_path = tf.placeholder(dtype=tf.string)
jpeg_data = tf.read_file(jpeg_path)
decode_jpeg = tf.image.decode_jpeg(jpeg_data, channels=3)
with tf.Session() as sess:
for i, filepath_list in enumerate(filepath_lists):
output_filename = '%s_%s_%05d-of-%05d.tfrecord'%(FLAGS.dataset_name, split_name, i, len(filepath_lists))
with tf.python_io.TFRecordWriter(output_filename) as writer:
for j,filepath in enumerate(filepath_list):
sys.stdout.write('\r>> Converting image %d/%d'%(j+1, len(filepath_list)))
sys.stdout.flush()
image_data, image = sess.run([jpeg_data, decode_jpeg], feed_dict={jpeg_path:filepath})
example = image_to_tfexample(image_data, 'jpg', image.shape[0], image.shape[1], label_lists[i][j])
writer.write(example.SerializeToString())
print(' Finished: %s'%(output_filename))
※なんか分かりづらいコードになってしまいました…
TFRecordファイルの作成は、tf.python_io.TFRecordWriterクラスを使うとできます。
ソースコード全体は下記に置いてあります。
https://github.com/workpiles/convert_TFRecord
作ったデータセットの読み込み
train_image_classifier.pyやeval_image_classifier.pyで作成したデータセットを読み込むためには、下記の簡単な変更を加えればできます。
datasets/dataset_factory.pyの変更
【中略】
from datasets import ccb
datasets_map = {
'cifar10': cifar10,
'flowers': flowers,
'imagenet': imagenet,
'mnist': mnist,
'ccb' : ccb, #←データセット名の追加
}
ccb.pyの作成
あとは、追加したデータセット用のget_splitを実装すれば完了です。
これは、flowers.pyやmnist.pyなど、他のデータセットを元に作成すれば問題ないと思います。
きゅうり画像で転移学習
早速、きゅうり画像でVGG16で転移学習を試してみました。fc8,fc7を学習対象としています。
(fc6を含めるとHDDの空きがなくなってしまった…)
学習に使用したのは解像度80×80、3チャンネルの画像を6500枚です。
後のパラメータは適当に。
python train_image_classifier.py \ --train_dir=data \ --dataset_name=ccb \ --dataset_split_name=train \ --dataset_dir=/tmp/ccb\ --model_name=vgg_16 \ --checkpoint_path=/tmp/ckpt/vgg_16.ckpt \ --checkpoint_exclude_scopes=vgg_16/fc8,vgg_16/fc7 \ --trainable_scopes=vgg_16/fc8,vgg_16/fc7 \ --max_number_of_steps=1000 \ --batch_size=32 \ --learning_rate=0.01 \ --learning_rate_decay_type=fixed \ --save_interval_secs=300 \ --save_summaries_secs=300 \ --log_every_n_steps=100 \ --optimizer=rmsprop \ --weight_decay=0.00004
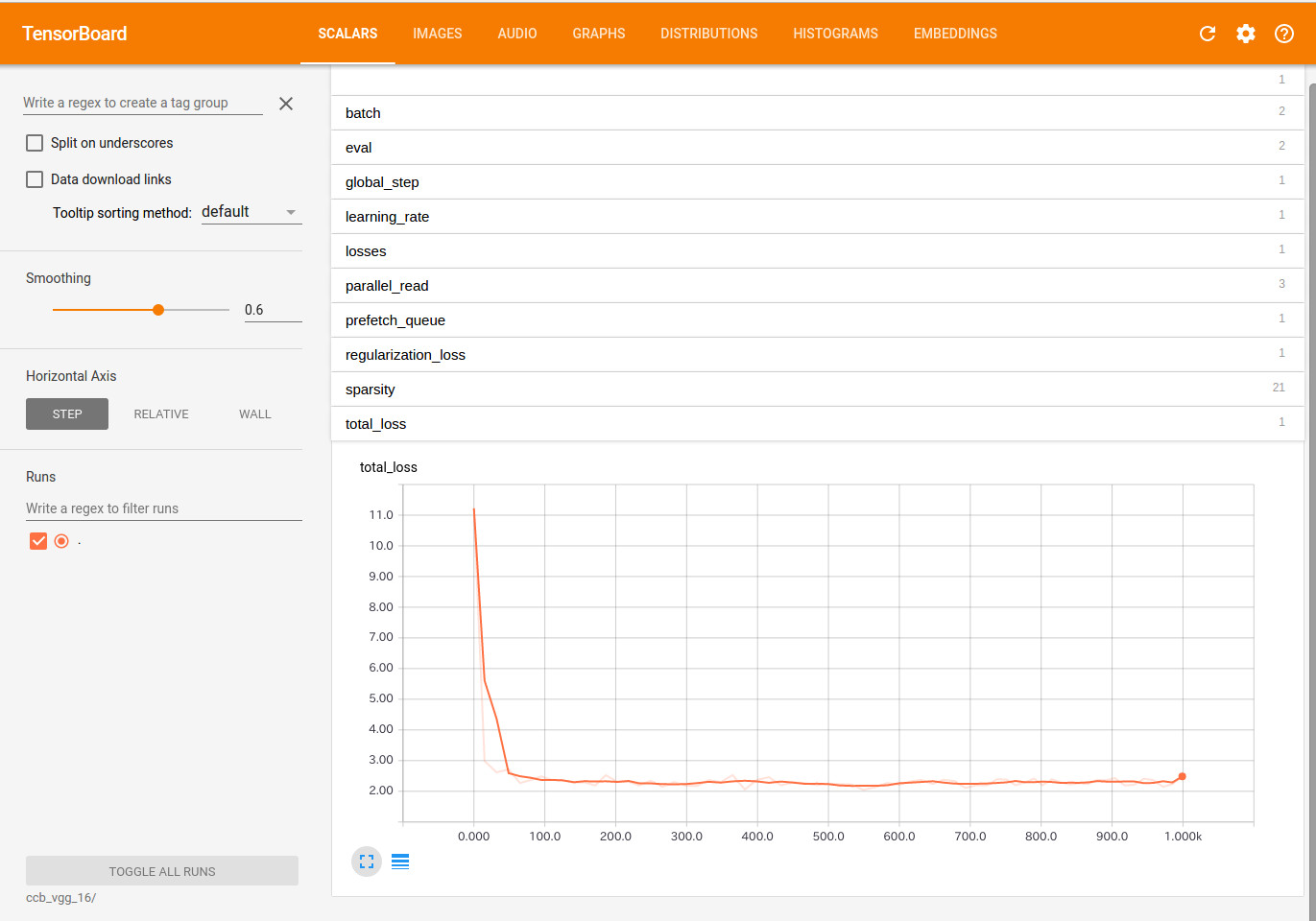
損失はsoftmax_cross_entropyで、200ステップ当たりで収束している感じです。
結果
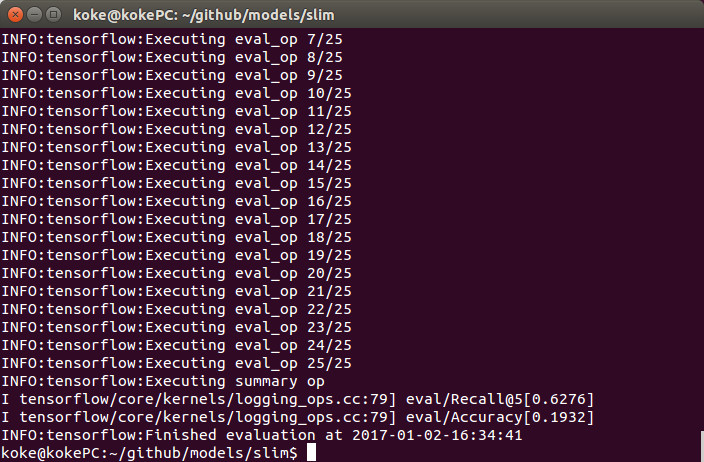
テスト画像2500枚に対して、10クラスに識別した場合の結果は、下記の通りでした。
正答率:19.3%
予測上位5クラスに正解が含まれる確率:62.7%
うーん。いまいち。
あとがき
なんか転移学習のやり方が間違ってる気がしてしょうがない…。




Thanks for the great post! I just started working on TF-slim, but I’m in trouble with custom image data. I put my data like below, but it keeps making errors like “Invalid JPEG data” when I run download_and_convert_data.py. (Of course, I modified this file for my custom images)
starbucks
– star1
– 1.jpg
– 2.jpg
…
– star2
– 1.jpg
– 2.jpg
…
– star3
– 1.jpg
– 2.jpg
…
Can you see if I am doing this wrong?
Do I have to put list.csv file?
Can you please let me know your custom image data directory structure?
Please try my convert script.
< https://github.com/workpiles/convert_TFRecord>