キュウリの仕分け機【試作3号機】を作りました。試作2号機から、完全自動化を考えていたのですが、なかなかメカ的な部分が難しく一旦保留。
試作3号機は、開発コンセプトを「AIによる完全自動化」から「人間が行う作業をAIでサポートする」に変更して設計することにしました。
下の写真がほぼ完成した仕分けシステムになります。

テーブル型の装置になります。

テーブルにキュウリを置くとAIが判断した等級が表示されるという仕組みです。
テーブルはPCのディスプレイで、ラズパイにつながっています。

右側にはコントロールパネルを設置して、動作モードの切り替えや、キャリブレーションなどの操作ができるようになっています。
透明なコンパネの裏に見えるのはラズパイです。
今回は、作業者がテーブル上にキュウリを置くと自動的に等級を判断してくれるので、その結果を参考にしながら作業者が箱詰めを行うというシステムです。仕分けノウハウを持たない作業者でもAIの判断を利用して、素早く仕分け作業を行うことができる…ということを期待してます(まだ実環境では未評価)。
試作3号機で追加した主な機能
Webカメラでキュウリを撮影しTensorFlowで9ランクに分類するというのは試作2号機から変わっていませんが、下記機能を追加しました。
1.複数同時に仕分け
YOLO,SSD,Faster R-CNNなどの一般物体検出技術を使用して…ではなく、単純に画像処理で輪郭抽出しています。そのほうが、処理が軽くなるような気がしたので。テーブルにしたPCディスプレイのバックライトのおかげで、割と精度よくキュウリの位置を検出できています。

2.キャリブレーション機能
キュウリの仕分けルールは農家毎に異なります。また、品種や収穫時にによっても全体的に太め、細めだったりします。
実際の作業では、絶対的な長さや太さの判断を行っているわけではなく、その時期の傾向を考慮して相対的に各等級に仕分けしています。
そこで、長さ、太さをキャリブレーションできるような仕組みを考えてみました。
例えば、等級Mと判断する長さのウィンドウを18cm〜21cmぐらいの中で調整できるようにしています。
3.教師データ収集機能
AIが判定を間違えたキュウリをその場で教師データとして登録できる機能です。
これにより、使えば使うほどAIが賢くなっていくはず。
実装
<開発環境>
・OpenCV 2.4.9
・TensorFlow 1.0.1
・kivy 1.9.1
1.複数同時に仕分ける
複数同時に仕分ける方法は、まず、テーブル上のキュウリ画像から、キュウリ1本1本の画像を切り出します。そして、切り出した画像をTensorFlowに入力して結果を得るというやり方です。もちろん、TensorFlowは1本のキュウリ画像で学習を行っています。
・キュウリ1本の画像を切り出し
キュウリ画像の切り出しは、Webカメラの画像を白黒画像へ変換し、輪郭抽出を行うことで取得します。
この画像処理にはOpenCVを使用しています。

Webカメラ画像
#マスク画像の生成 def get_mask_from_threshold(image): gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) _, mask = cv2.threshold(gray, 60, 255, cv2.THRESH_BINARY) mask = cv2.bitwise_not(mask) #白黒反転 return mask
マスク画像
#輪郭抽出
def get_contours(mask):
contours, hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
area_rects = []
for i in xrange(len(contours)):
area = cv2.contourArea(contours[i])
if area < 2000: #小さい輪郭はキュウリじゃないとして弾く
continue
center, size, angle = cv2.minAreaRect(contours[i])
if angle < -45: #縦横が逆のものは回転して修正
size = tuple(reversed(size))
angle = angle + 90
area_rects.append((center, size, angle))
return area_rects
上記のコードで、キュウリの輪郭に外接する矩形の中心、高さ、幅、傾きが得られます。
後はこの情報を元に、カメラ画像からキュウリ画像を切り抜けば良いだけです。
・TensorFlowへの入力画像
OpenCVを使って切り出した画像はサイズがバラバラです。単純に、画像をリサイズする方法もありますが、それだとサイズ感やアスペクト比がおかしくなってしまいます。
異なるサイズの画像を扱う方法(可変長→固定長に変換する方法)として、Spatial Pyramid Poolingとう手法もありますが、今回は、下記のように固定サイズ(340×100)のキャンバスに貼り付ける方法でやってみることにしました。これなら、人間が見てもサイズ感がなんとなくわかるのでニューラルネットワークでも分類できるんじゃないかと考えたわけです。

高さ340px幅100pxの黒い背景にキュウリ画像を貼り付けた画像
(7枚を並べた例です。TensorFlowには1本ずつ入力します)
def get_pasted_image(image): canvas = np.zeros([340, 100, 3], dtype=np.uint8) h,w,c = image.shape h = 340 if h > 340 else h w = 100 if w > 100 else w canvas[0:h,0:w,0:3] = image[0:h,0:w,0:3] return canvas
2.キャリブレーション機能
これはまだ実験中。
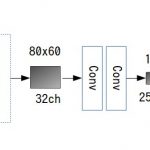
NNを下記のような構成にして、畳込み層で抽出した特徴量とキュウリの長さ、幅、表面積の値とをくっつけて全結合層の入力としています。これにより、長さや幅と言った入力値を調整することで、最終的な予測ラベルを調整出来るのではないかと考えたわけです。
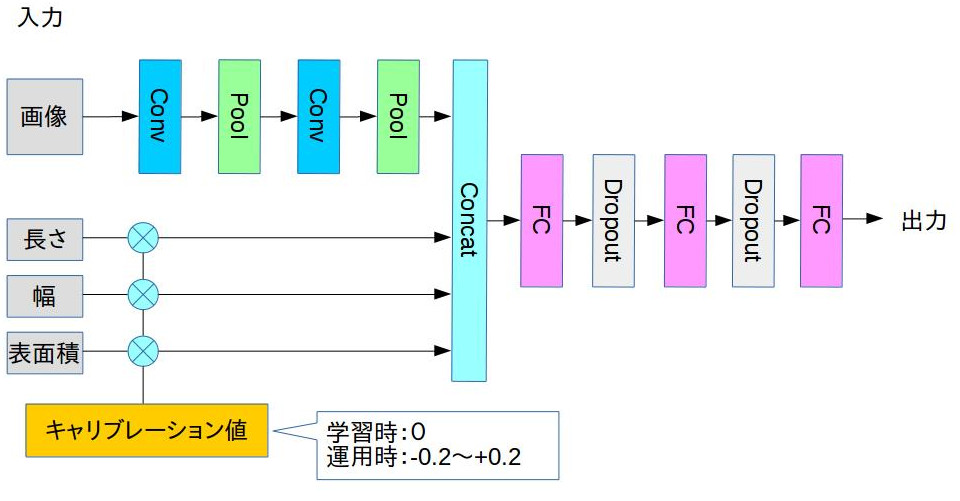
NN構成
def inference(images, lengths, widths, areas, keep_prob, is_training,
hidden1, hidden2, kernel_size, fc_size):
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(0.0005),
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01)):
with slim.arg_scope([slim.batch_norm], decay=0.9,
updates_collections=None, is_training=is_training):
net = slim.conv2d(images, hidden1, [kernel_size, kernel_size],
normalizer_fn=slim.batch_norm, scope='conv1')
net = slim.max_pool2(net, [2, 2], scope='pool1')
net = slim.conv2d(net, hidden2, [kernel_size, kernel_size],
normalizer_fn=slim.batch_norm, scope='conv2')
net = slim.max_pool2(net, [2, 2], scope='pool2')
widths = tf.reshape(widths, [-1, 1])
lengths = tf.reshape(lengths, [-1, 1])
areas = tf.reshape(areas, [-1, 1])
net = tf.concat([lengths, widths, areas, net], 1)
net = slim.fully_connected(net, fc_size, scoep='fc1')
net = slim.dropout(net, keep_prob=keep_prob, scope='dropout1')
net = slim.fully_connected(net, fc_size//2, scoep='fc2')
net = slim.dropout(net, keep_prob=keep_prob, scope='dropout2')
net = slim.fully_connected(net, 10, activation_fn=None, scoep='output')
return net
基本的にはこの構成をベースにチューニングを行っていきました。
中間結果
取り敢えず今のところ約80%ほどの正答率で分類することが出来るようになりました。
キャリブレーションの仕組みの方は…いまいちと行ったところ。
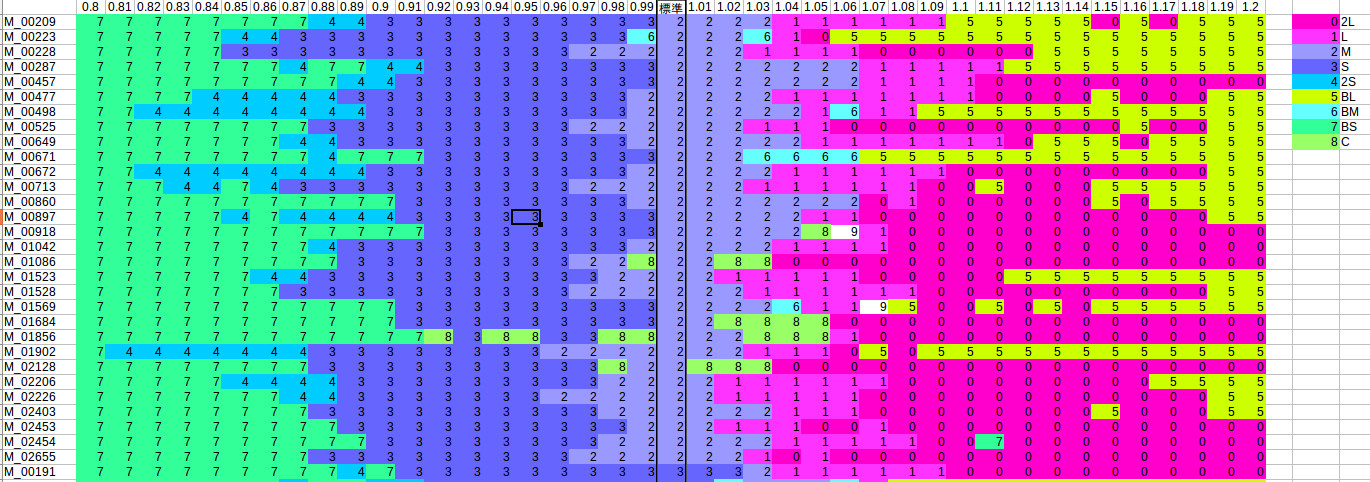
等級Mサイズのキャリブレーション結果
上記の結果は、等級Mサイズのキュウリのキャリブレーション結果です。横軸が調整した比率(例:1.2なら長さ、太さ共に1.2倍)です。比率を小さくしていくに連れてM→S→2Sとなってほしくて、逆に大きくした場合は、M→L→2Lとなって欲しいのですが。
全く不可能というわけではなさそうですが、B品と判断されてしまう場合もあるようです。
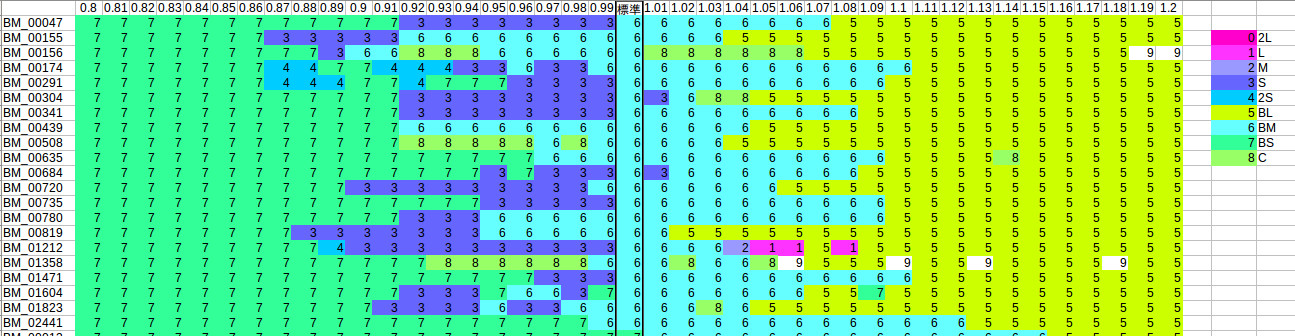
等級B中サイズのキャリブレーション結果
等級B中の場合も、比率を小さくするとA品と判断されてしまう場合が多いようです。
と今回はここまで。データセットやハイパーパラメータチューニングについてはまた今度書きます。
あとがき
今年もMakerFaireTokyoに出展します。もちろん、今回もTensorFlowを使ったキュウリ仕分け機ですね。
試作3号機を展示する予定です。楽しみ。
![]()
ではでは〜。