きゅうり仕分け機の試作2号機が完成しました。
前回は識別部分まででしたが、残りの機能の実装が完了しました。
まだまだ実用できるレベルではないのですが、一応仕分けは出来るようになりました。
認識率について
試作2号機では、3つのカメラ画像(上、下、側面)のセットを入力として、TensorFlowで学習させています。

学習時間なども考慮(自宅のデスクトップPCで試しているので遅い…)して、解像度を80×80にして、上下側面の画像をグレースケールに変換して学習画像としています。学習画像を7000枚、それとは異なるテスト画像を1500枚用意しました。
(それでも2,3日はかかるし、ちょっと隠れ層を増やそうもんなら…)
数日で学習が終わりそうな範囲でパラメータを変えて何度も試してみたところ、認識率は最大95.5%まで行きました。ただ、実機に実装しての認識率は7〜8割程度な気がするので、過学習気味な気もします。
(おそらく周りの明るさやカメラ位置の微妙なズレが原因?時間帯をずらして学習用画像を集めたほうがよかった?)
試してみて感じたことは、
・解像度は結構大事
・学習変数の初期値は大事
・batch normalizationは優秀
・入力画像はやっぱり沢山あったほうが良い
・可能であれば入力のばらつきを抑える工夫をした方が効率がいい
(ライトを使って入力画像の明るさを揃えるとか)
・人間だとうっかり見落としてしまう部分も見てるから気をつけろ
(画像のピンぼけした背景など、全然気にしてなかった部分も判定に使ってた…)
学習データの公開
試作1号機の学習画像セットと今回の学習画像セットを下記に置いておきます。
(ファイルサイズがデカすぎて低解像度しかアップ出来ませんが…)
https://github.com/workpiles/CUCUMBER-9
TensorFlowのチュートリアル終わって、MNISTもCIFAR-10も飽きた人はぜひキュウリでもやってみて下さい(笑
(…そしていいパラメータ見つけたら教えてくれるとありがたいっす)
あとがき
試作2号機をMakerFaireTokyo2016に出展します!
それが終われば一応2号機の開発は終了する予定です。
そして、3号機の開発に取り掛かろうかなと考えています。
次の課題は、傷や色合い等の認識率向上と仕分け速度アップです。
まだまだやること山積みですね(-_-;)



Maker Faire Tokyo 2016 で作品を拝見しました.
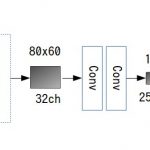
公開されているデータを単純なネットワークで試したところ,
短い学習時間で95%以上の精度が出ました.
https://github.com/AAmmy/CUCUMBER-9
畳み込み等行っていないので実際の環境では識別率がかなり下がるかもしれませんが,
よければ参考にしてみてください.
MFT2016ではブースに訪問して頂いてありがとうございました。
>短い学習時間で95%以上の精度が出ました.
CNNじゃなくても精度出るんですね!
今までは割と“ネットワークを深くすれば精度があがるだろう”的な考えで実験を進めていましたが、別のアプローチの方が有効なのかもしれませんね。
githubにアップして頂いたソースコードを見て勉強させて頂きます^^
情報提供ありがとうございました。