GCP Cloud MLを使ってハイパーパラメータチューニングをやる方法です。
普段の開発環境にはGPU付いてないので、ここぞという時はGCP(Tesla K80)使ってます。お値段は1時間使って約1.5ドル(160円)ほどです。
※ちなみにTesla K80のお値段って80マンもするんですね。たかっ!
ハイパーパラメータチューニングみたいにPCぶん回さないといけない場合も、CPUだと厳しいのでGCPを使います。
CloudMLを使ってトレーニングができる環境が構築済みという前提で話を進めていきます。
準備
まずは、CloudML上でハイパーパラメータチューニングを行うためにいくつか準備が必要です。
1.パラメータを実行時オプションから指定出来るようにソースコードを書き換える
チューニング対象のパラメータをプログラム実行時のオプションで指定できるように書き換えます。
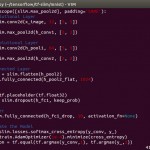
例えば、下記のように学習率(learning_rate)やフィルタ数(hidden)、活性化関数(activation_fn)などをtf.app.flagsとして定義し、推論モデル構築の際に処理を切り替えられるようにしておきます。
...(中略)
tf.app.flags.DEFINE_float('learning_rate', 1e-3, '')
tf.app.flags.DEFINE_integer('hidden', 32, '')
tf.app.flags.DEFINE_string('activation_fn', 'relu', '')
...(中略)
def inference(x, hidden, act_fn):
if act_fn=='elu':
activation = tf.nn.elu
elif act_fn=='sigmoid':
activation = tf.sigmoid
else:
activation = tf.nn.relu
with slim.arg_scope([slim.conv2d, slim.fully_connected], activation_fn = activation):
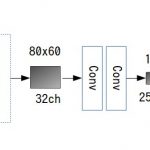
net = slim.conv2d(x, hidden, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.flatten(net)
net = slilm.fully_connected(net, 512, scope='output')
net = slilm.fully_connected(net, CLASSES, activation_fn=None, scope='output')
return net
...(中略)
logits = inference(x, FLAGS.hidden, FLAGS.activation_fn)
loss = loss(logits, labels)
train_op = train(loss, FLAGS.learning_rate)
2.チューニング結果のメトリクスを指定
チューニングが上手くいったかどうかの指標をtf.summary.scalarに“training/hptuning/metric”という名前で設定します。
(これはデフォルト設定。タグ名を変えた場合ばconfig.yamlで指定する)
CloudMLは、この値が最大(又は、最小)になるようにチューニングを実行します。
例えは、検証用データセットに対する正答率などを指標にしたりします。
...(中略)...
tf.summary.scalar("training/hptuning/metric', validation_accuracy)
ちなみにチューニングでは、一番最後に登録したサマリーが参照されるようです。
3.サマリーの保存場所の指定
チューニングのトライアル毎にtf.summaryの出力などを保存しておくフォルダを切り替える必要があります。
下記関数を定義して、出力パスを下記のように切り替えます。
import os
import json
def makeTrialOutputPath(output_path):
env = json.loads(os.environ.get('TF_CONFIG', '{}'))
taskInfo = env.get('task')
if taskInfo:
trial = taskInfo.get('traial', '')
if trial:
return os.path.json(output_path, trial)
return output_path
これで指定したパス(output_path)以下にトライアルIDごとのフォルダが作成されます。
4.config.yamlにチューニング条件を記述
config.yamlにチューニングの条件を記述します。
config.yaml
trainingInput:
scalerTier: BASIC_GPU
hyperparameters:
goal: MAXIMIZE #目指す方向 MAXIMIZE or MINIMIZE
maxTrials: 50 #最大トライアル数
maxParallelTrials: 1 #並列実行数
params: #チューニングパラメータ
- parameterName: hidden
type: INTEGER
minValue: 8
maxValue: 64
scaleType: UNIT_LINEAR_SCALE
- parameterName: learning_rate
type: DOUBLE
minValue: 0.00001
maxValue: 0.01
scaleType: UNIT_LOG_SCALE
- parameterName: activation_fn
type: CATEGORICAL
categoricalValues: ['elu', 'sigmoid', 'relu']
- parameterName: keep_prob
type: DISCRETE
discreteValues: [0.1, 0.5, 0.9]
チューニングパラメータは、下記のとおりです。
- type:INTEGER
- 整数のパラメータ。下限をminValue、上限をmaxValueで指定する。
- type:DOUBLE
- 実数のパラメータ。下限をminValue、上限をmaxValueで指定する。
- type:CATEGORICAL
- リスト内から選択。categoricalValuesで指定したリスト(string)から選択する。
- type:DISCRETE
- 実数のパラメータをリスト内から選択。discreteValuesで指定したリストから選択する。値は昇順じゃないといけない。
あと、scaleTypeは、値のスケーリング方法を指定するパラメータで,UNIT_LINEAR_SCALE(線形関数的増加)、UNIT_LOG_SCALE(対数関数的増加)、UNIT_REVERSE_SCALE(逆対数的増加)を指定できます。
5.ジョブの登録
最後にジョブの登録ですが、–configオプションで先ほどのconfig.yamlを指定してあげるだけで、あとは通常のトレーニング時と同じです。
gcloud ml-engine jobs submit training $JOB_NAME \ --job-dir gs://(作業場所) \ --module-name trainer.train \ --package-path trainer \ --region us-central1 \ --config config.yaml \ -- (中略)
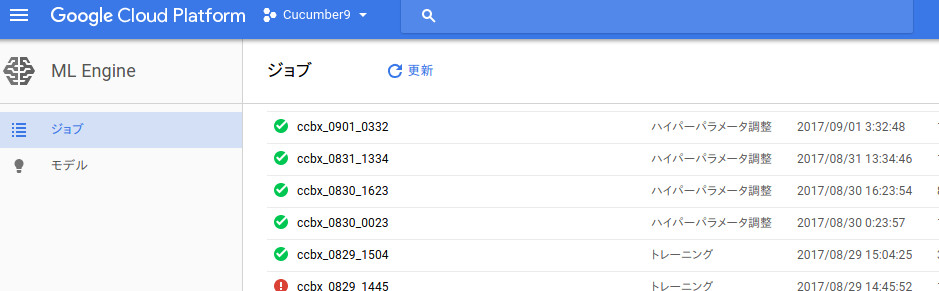
登録が成功すると、GCPコンソール上で“ハイパーパラメータ調整”としてジョブが登録されていることが確認できます。
チューニング結果の確認
ハイパーパラメータチューニングの結果は、GCPコンソールで確認でき、ジョブ詳細の“トレーニング出力”の欄に結果の一覧が表示されます。
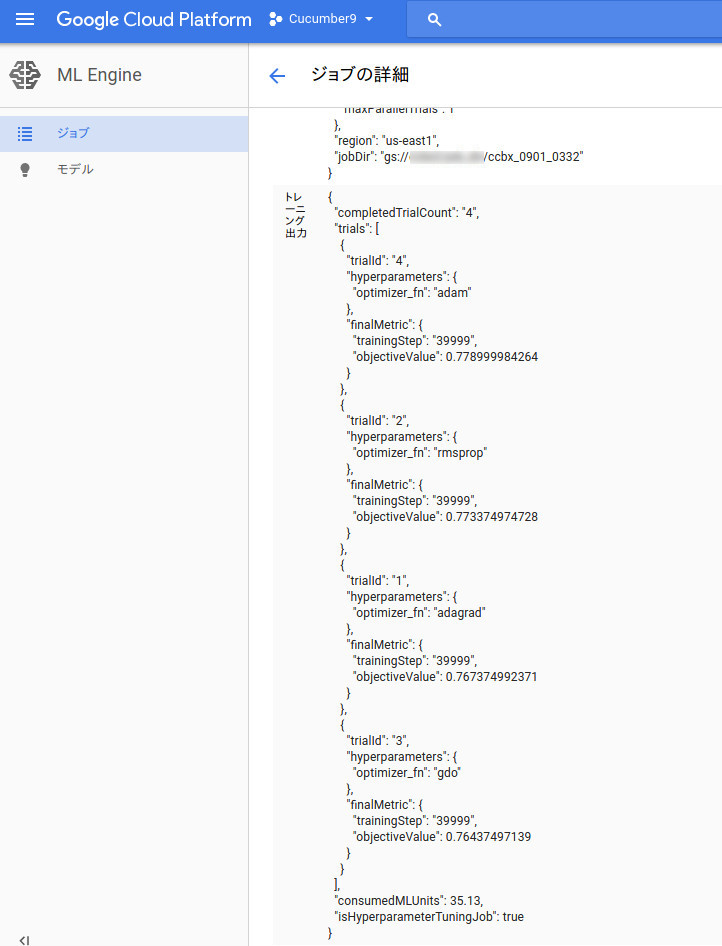
また、“3.サマリーの保存場所の指定”がちゃんとできていれば、サマリーの出力は“トレーニング出力”欄に出ているトライアルIDごとのフォルダに保存されています。
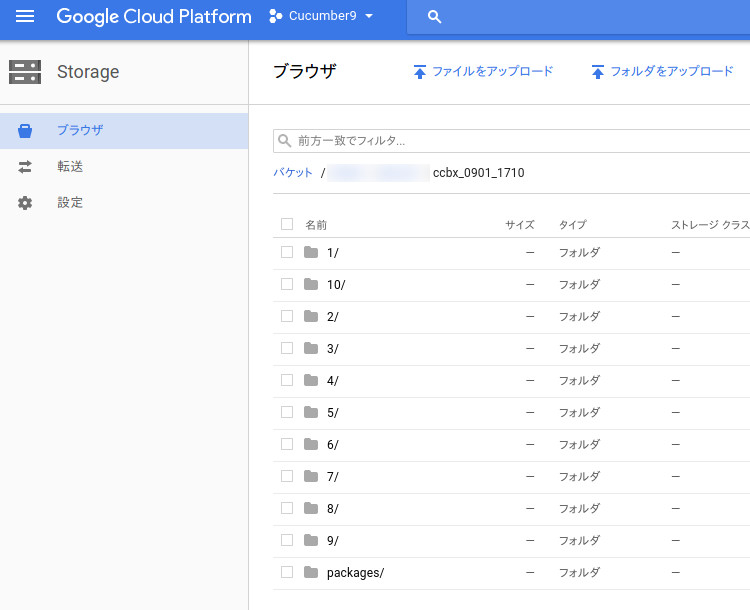
以上です。
GPU(Tesla K80)使ったのに遅い!
ちなみにGPU使ったのに思ったよりスピードアップしない場合があります。
CPU(Core i-5 3.2GHz)と比較して2倍弱しかスピードアップしない…Tesla K80のパワーはそんなもんじゃないはず。
原因の一つとしては、教師データをストレージからの読み出すスピードが遅いことが挙げられます。データ読み出し部分と学習(順伝搬と逆伝搬の計算)部分とを別けて計測してみると、データ読み出し時間はローカルPC(SSD使用)は0.005秒なのに対して、CloudML(たぶんHDD)では0.095秒もかかっていました。学習部分の時間はローカルPC(CPU)は0.264秒で、CloudML(GPU)は0.02秒ともちろんGPUの圧勝でした。CloudMLでは学習開始時にCloudStorageから教師データ一式を実行環境にコピーして、そこから読み出すようにしています。CloudStorageから読み出すと更に遅くなります。
3層程度の小さなCNNの場合は、読み出し時間の影響の方が大きいのであまりTesla K80の恩恵を受けることができないという…。ちなみに、
GPU動いてない時間もちゃんとGPU料金で課金されてるからね(;_;)