ニューラルネットワークの量子化をTensorFlowで試してみました。
ニューラルネットワークの量子化とは、一般的に32bit(64bit)浮動小数点で表現される重みなどのパラメータを、ざっくり減らして数ビット(1〜8bit)で表現する手法です。量子化することで、計算の高速化(特にFPGAや専用LSI)や学習済みモデル容量の削減などが期待できます。
今回は試しにMNISTのニューラルネットワークを8bit量子化してみました。ネットワークの訓練時は通常の不動小数点で行い、学習後に学習済みのパラメータの量子化しています。
※量子化したまま学習する手法もあるようですが、そちらはまだ勉強不足なのでよくわかりません。
【参考】
FPGAでDeep Learningしてみる – きゅうりを選果する
YouTube : TensorFlow User Group ハード部 #1
How to Quantize Neural Networks with TensorFlow
【環境】
・Ubuntu 16.04
・TensorFlow v1.3.0
・bazel 0.4.5
・python 2.7
取り敢えず試す
取り敢えず、32bit不動小数点の配列を量子化してみます。
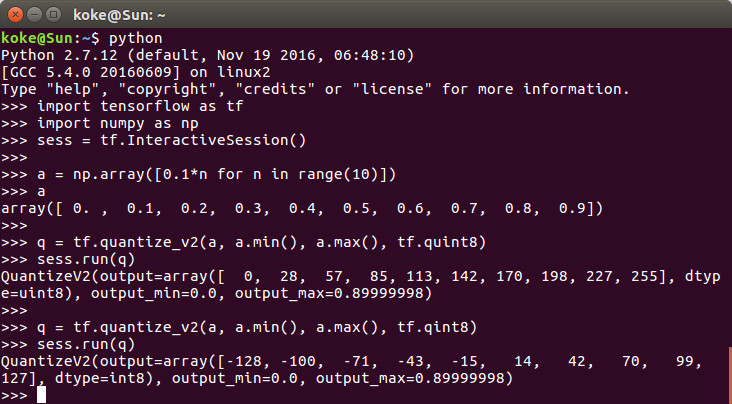
0.0〜0.9が格納された配列aを、tf.quantize_v2を使って8bitに量子化しています。
tf.quint8では(0〜255)、tf.qint8では(-128〜127)の値を取ります。
MNISTを量子化する
1.まずは普通に学習する
TensorFlowチュートリアルDeep MNIST for Expertsを使って、学習を行いました。
学習の最後に、学習済みの重みなどのパラメータとグラフ構成をファイルに保存しています。
train.py
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
def weight_variable(shape, name):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name=name)
def bias_variable(shape, name):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name=name)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(
x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
x = tf.placeholder(tf.float32, shape=[None, 784], name='input')
y_ = tf.placeholder(tf.float32, shape=[None, 10])
W_conv1 = weight_variable([5, 5, 1, 32], 'W_conv1')
b_conv1 = bias_variable([32], 'b_conv1')
x_image = tf.reshape(x, [-1, 28, 28, 1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64], 'W_conv2')
b_conv2 = bias_variable([64], 'b_conv2')
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 * 7 * 64, 1024], 'W_fc1')
b_fc1 = bias_variable([1024], 'b_fc1')
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10], 'W_fc2')
b_fc2 = bias_variable([10], 'b_fc2')
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
softmax = tf.nn.softmax(y_conv, name='softmax')
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in xrange(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(
feed_dict={x: batch[0],
y_: batch[1],
keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images,
y_: mnist.test.labels,
keep_prob: 1.0
}))
saver.save(sess, 'model/model.ckpt')
tf.train.write_graph(sess.graph.as_graph_def(), 'model/', 'graph.pb')
2.freeze_graph
次にfreeze_graphで、重みなどの変数を定数に変換してグラフ情報と一緒に固めておきます。
コレはtensorflow/python/tools/freeze_graphを使うと簡単に変換できるます。
まずはツールのビルド。githubからcloneしたTensorFlowリポジトリ内で下記コマンドを実行する。
ビルドにはbazelを使うのでない場合はインストールしておく。
※v1.0以降はSavedModelが推奨されているが、そちらで変換するの後の量子化ツールが使えなかった
bazel build tensorflow/python/tools:freeze_graph
ビルドが完了したら下記コマンドを実行。
bazel-bin/tensorflow/python/tools/freeze_graph \ --input_graph=<path>/graph.pb \ --input_checkpoint=<path>/model.ckpt \ --output_graph=frozen_graph.pb \ --output_names=softmax
3.量子化
最後に量子化を行います。TensorFlowには量子化するツールも準備されているのでそれを使います。
まずはツールのビルド。
bazel build tensorflow/tools/quantization:quantize_graph
ビルドが完了したら下記コマンドを実行。
bazel-bin/tensorflow/tools/quantization/quantize_graph \ --input=frozen_graph.pb \ --output_node_names=softmax \ --print_nodes \ --output=quantized_graph.pb \ --mode=eightbit
これでネットワークが8bit量子化されます。
ファイルサイズを比較してみると、frozen_graph.pbが13MBでquantized_graph.pbが3.2MBとなり、約2割ほどのサイズまで縮小できました。
何が変わったのか
quantize_graphで何が変更されたのか見てみます。
pbファイルのネットワーク構成を確認するためにはsummarize_graphツールが使えます。
ツールのビルドは下記の通り。
bazel build tensorflow/tools/graph_transforms:summarize_graph
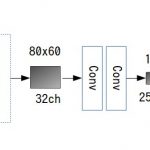
ツールを使うとグラフ構成が確認できるが、ごちゃごちゃした出力なので簡単な図にすると下記のような感じになる。

入力された画像はtf.quint8に量子化されて処理される。ただし、Add、ドロップアウトオペレーションはdequantizeされたfloatで計算されていた。
あと、QuantizedConv2dとQuantizedMatMulの出力がtf.uint32になるので、直後にrequantizeオペでtf.uint32をtf.quint8に変換する処理が追加されていた。上記の図では割愛したが、最終段の出力はdequantizeされたfloat値になる。
動かしてみた
最後にMNISTのテストデータを使って、量子化による認識率の低下具合や実行時間を確認しました。
|量子化前|量子化後
ーーーー+ーーーー+ーーーーー
正答率 |99.22% | 99.20%
実行時間|4.88s | 7.16s
サイズ | 13MB | 3.2MB
認識精度については特に低下は見られませんでした。
実行時間はだいぶ遅くなった感じです。Quantize-Dequantize、Requantizeオペの追加などが影響しているのでしょうか?
まあ、CPUで動かしてるのでこんなものかなとも思います。FPGAで試してみたいなー。
モデルサイズはだいぶ小さくなるので、スマホアプリなどに実装する際は量子化も考えてみようかと。
おまけ:Python APIについて
APIドキュメントみてもQuantize関連のAPIが少ないけど、gen_nn_ops.py、gen_math_ops.py辺りにQuantize関連APIの定義はあるので、importすれば使える。
2値化についてはIssues:Binary ops

![[GCP]Cloud Machine Learningを使ってハイパーパラメータチューニング](http://workpiles.com/wordpress/wp-content/uploads/2017/09/hptuning-150x150.jpg)
