最近、ちょっと『SSD:Single Shot MultiBox Detector』を勉強中です。ディープラーニングを使った一般物体検出のアルゴリズムで、写真の“どこに”“なにが”写っているかを推測するアルゴリズムです。
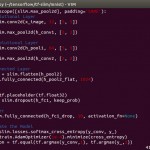
今回は、TensorFlowで物体領域予測を試してみました。SSDについても書いていますが、今回試したこととはほとんど関係なかったりします(参考にはしていますが…SSD難しい)
一般物体検出アルゴリズムについて
一般物体検出アルゴリズムについては、下記ブログで分り易く紹介されています。
Deep Learningによる一般物体検出アルゴリズムの紹介
どのアルゴリズムもarXivに論文が上がっています。
SSDから読み始めると、Faster R-CNN、Fast R-CNN、MultiBox、YOLO辺りは芋づるで読む必要が出てくるので、全てを理解するのは結構大変だと思うわけです。というか、まだ理解できてないです( ・ั﹏・ั)
SSD:Single Shot MultiBox Detector
SSDについては論文を読んだ後に、下記を見るとイメージが掴みやすかったです。
(何喋ってるかはさっぱりですがアルゴリズムをイメージで説明してくれているので、「あっそういうことか!」ってなると思います)
SSDの物体領域提案(region proposal)について
SSDでは、物体が存在している領域を推測するために、CNNで抽出した画像特徴マップ(feature map)を使用しています。
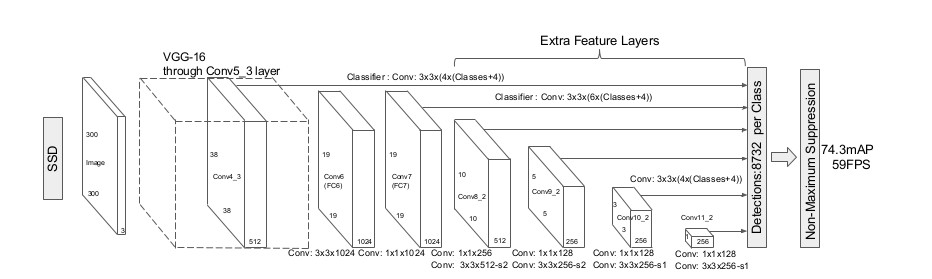
(SSD300の場合)まず300×300の入力画像から、VGG-16のConv5_3層で出力される特徴マップ(38×38)を取得します。
この特徴マップを使って、入力画像を38×38分割したぐらいの大きさの物体領域候補を検出します。
次に、この特徴マップを畳み込んで少し小さい特徴マップ(19×19)を取得します。そして、取得した19×19の特徴マップを使って、入力画像を19×19分割したぐらいの大きさの物体領域候補を検出します。
このように、特徴マップを少しずつ小さく畳み込んでいくことで、いろいろなスケールの物体領域候補を検出できるようにしています。
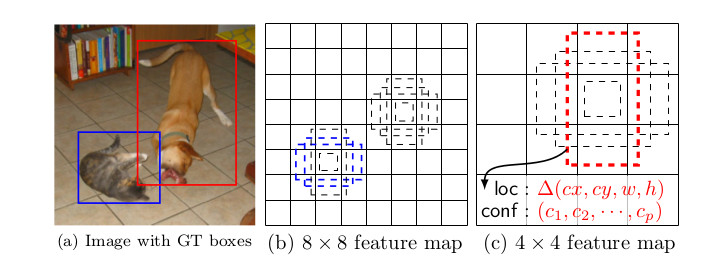
特徴マップと元画像との対応は、アスペクト比の異なる複数のBoundingBox(default boxと言う)を介して行います。
(ココらへんはFaster R-CNNのAnchorsの考え方を勉強しておくと理解しやすいです)
上記画像(b)の例だと、8×8の特徴マップの各特徴点(*1)に対し、アスペクト比の異なる3種類のDefault Boxをあてがって、元画像の物体領域(ground truth boxes)の検出を行なっています。8×8の特徴点で3個のDefault Boxなので、8x8x3個の物体領域候補の検出結果(*2)を取得できることになります。これを複数のサイズの特徴マップに対して行います。特徴マップが小さくなることで、大きな物体領域を検出できることがわかります。
*1:正確には、3×3のSliding window
*2:出力は、Ground truthとDefault boxとの位置のオフセット(中心のX座標、中心のY座標、幅、高さ)の4値とクラス分類の推測値になります。物体位置とクラス分類結果を一つのネットワークで学習&出力するというのがSSDアルゴリズムの特徴となっているようです(ここから、Single Shotと名付けられたのかな)。ちなみに、YOLOも1つのネットワークで学習を行うアルゴリズムです。Fast R-CNNやFaster R-CNNは、物体領域検出とクラス分類を複数のネットワークをパイプラインで繋ぐことで実現しています。ココらへんも、ちゃんと理解できたらそのうちブログに書きたい。
学習:損失関数
損失関数は下記の通りです!「お、おう・・・」
数式だけ貼っても意味がないので、ココは論文を読んで下さい(汗
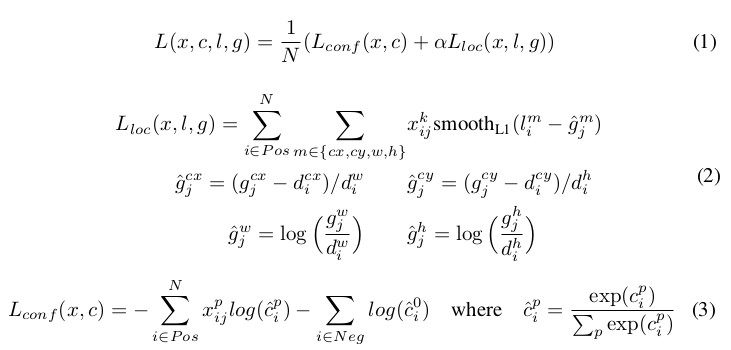
位置の損失部分(2の式)だけを簡単に説明すると、あるDefault box(DB)とGround truth(GT)とのオフセットを下記の通り求めます。
中心のX座標のオフセット=(GTの中心のX座標 – DBの中心のX座標)/ DBの幅
中心のY座標のオフセット=(GTの中心のY座標 – DBの中心のY座標)/ DBの高さ
幅のオフセット=log(GTの幅/DBの幅)
高さのオフセット=log(GTの高さ/DBの高さ)
そして各オフセットのsmooth_l1を算出します。smooth_l1は『Fast R-CNN』の論文に記載があります(簡単な計算です)。
XijはGTとDBの領域が一致しているかの指標で、Jaccard係数が0.5以上なら一致(Xij=1)、それ以外は不一致(Xij=0)としています(←もしかしたら間違って認識してるかも…自信なし)。
後は、これらを合計した値が位置の損失値になります。
なんとなく理解できた(ような気がする…)ので早速試してみよう
とは言え、まだSSDを完全に理解した訳ではないし実装とかかなり大変そうなので、問題をうんと小さくして物体位置検出だけやってみることにしました。
だたし…問題を小さくし過ぎたせいで、もはやSSD関係なくなっちゃったわけで…単純なニューラルネットワークを使った回帰をやってみたレベルの内容です(汗
問題定義
下記の様な「キュウリ画像」からキュウリのある位置を推測する。
なぜキュウリなのかと言えば、単純に沢山画像持ってるからですw

【ポイント】
・画像内にキュウリは必ず1本
・キュウリのある位置も大体同じ(上半分に収まる辺り)
*ちなみにこの程度ならOpenCVを使った簡単な画像処理(適当なフィルタかけて2値化)で出来そうだけど、勉強目的なのであえて機械学習なのであるw
モデル
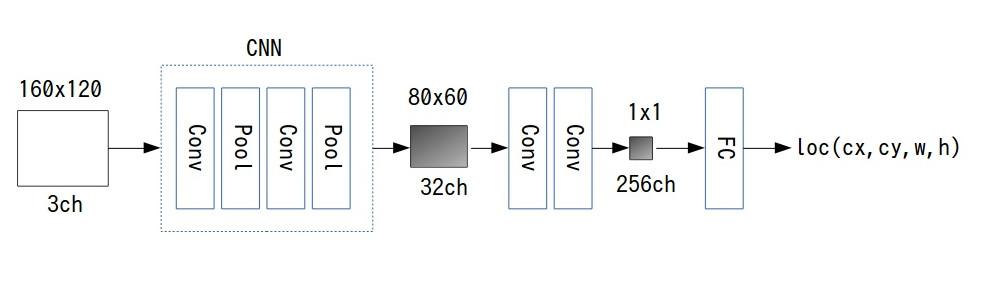
今回の画像は、Default boxのスケール、アスペクト比を変えて探索する必要がないので、そこら辺を全て取っ払って、SSDの最終段である1x1x256の特徴マップだけを使って、160×120のDefault boxとGround truthとのオフセットを推測するというモデルです。
TensorFlowで書くと下記の通りです。
TensorFlow r1.0使用
slim = tf.contrib.slim
def inference(inputs):
x = tf.reshape(inputs, shape=[-1, 120, 160, 3], name='inputs')
with slim.arg_scope([slim.conv2d], weights_regularizer=slim.l2_regularizer(0.0005)):
net = slim.conv2d(x, 32, [5, 5], scope='conv1')
net = slim.conv2d(net, [2, 2], scope='pool1')
net = slim.conv2d(net, 32, [5, 5], scope='conv2')
net = slim.conv2d(net, [2, 2], scope='pool2')
net = slim.conv2d(net, 64, [3, 5], padding='VALID', stride=[3, 5], scope='conv3')
net = slim.conv2d(net, 256, [10, 8], padding='VALID', scope='conv4')
net = slim.conv2d(net, 4, [1, 1], padding='VALID', activation_fn=None, scope='fc')
net = tf.reshape(net, [-1, 4], name='outputs')
return net
損失関数
損失関数は下記の通り。
今回は単純に、Default boxを画像全体としたので、必ずGTはDB内に存在するため、DBとGTの一致は無視しています。
def loss(logits, gt): def smooth_l1(x): smooth_l1_sign = tf.cast(tf.less(tf.abs(x), 1.0), tf.float32) smooth_l1_option1 = tf.multiply(tf.multiply(x, x), 0.5) smooth_l1_option2 = tf.subtract(tf.abs(x), 0.5) smooth_l1_result = tf.add(tf.multiply(smooth_l1_option1, smooth_l1_sign), tf.multiply(smooth_l1_option2, tf.abs(tf.subtract(smooth_l1_sign, 1.0)))) gt = tf.cast(tf.divide(gt, tf.constant([160, 120, 160, 120])), tf.float32) gt_cxcy, gt_wh = tf.split(gt, [2, 2], 1) gt_cxcy = tf.substract(gt_cxcy, 0.5) gt_wh = tf.log(gt_wh) gt = tf.concat([gt_cxcy, gt_wh], 1) offset = tf.subtract(logits, gt) total_loss = tf.reduce_sum(smooth_l1(offset)) return total_loss
学習
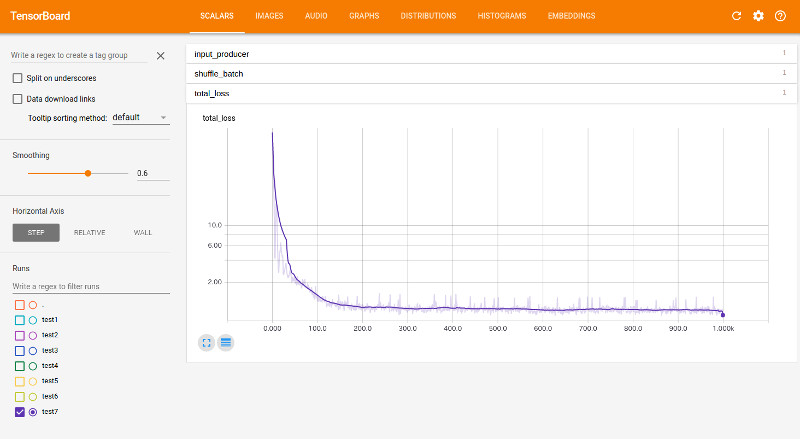
教師画像を3000枚用意して、バッチサイズ100枚で1000Step回してみました。
評価
赤枠:Ground Truth
青枠:予測したBounding Box

なんかGround Truthより上手く領域切り出せてるような・・・
ちなみにGround Truthはマウスでポチポチしながら作ったので、集中力が切れるとかなり適当。
あとがき
まだまだ初歩的なことしか出来ないですが、位置検出についてちょっとはわかってきなような気がします。
次は複数の物体検出も試してみようかな。
ところで、TensorFlow r1.0にアップデートしてからなんか終了時にコアダンプで落ちるようになった…
なんでだろう。ソースコードからビルドした方がいいのかな〜。実行時のWarningも消えてスピードアップ出来るっぽいし。

![[GCP]Cloud Machine Learningを使ってハイパーパラメータチューニング](http://workpiles.com/wordpress/wp-content/uploads/2017/09/hptuning-150x150.jpg)