前回紹介した「きゅうりの自動選別機」の撮影台を使って順調に画像データを集めている途中ですが、並行してTensorFlowでの学習もやり始めたところです。
さて、学習を始めるに当たり、Batch Normalizationという早く学習を進める手法があるということで試してみました。
Batch Normalization
Batch Normalizationとは、ミニバッチごとに平均が0,分散が1になるように正規化を行う手法で、
・学習が早く進む
・初期値依存性を軽減できる
といった利点があるそうです。
詳しくは、論文が公開されています。
(batch normalizationで検索するとトップに出てくると思います)
また、詳しく解説してくださっている下記ブログがとても参考になりました。
Qiita – [Survey]Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Qiita – 多層ニューラルネットでBatch Normalizationの検証
きゅうり仕分け学習にも使ってみる
ということで、早速きゅうりの仕分けの学習にも導入してみました。
実装
Batch Normalizationの実装は下記サイトを参考にさせてもらいました。
また、TensorFlowではver0.8.0から(?)tf.nn.batch_normalizationというAPIが追加されています。
【参考】
Qiita – Batch Normalizationによる収束性能向上
stackoverflow – How could I use Batch Normalization in TensorFlow?
・Batch Normalization
def batch_norm(x, is_training, decay=0.9, eps=1e-5):
shape = x.get_shape().as_list()
assert len(shape) in [2, 4]
n_out = shape[-1]
beta = tf.Variable(tf.zeros([n_out])
gamma = tf.Variable(tf.ones([n_out])
if len(shape) == 2:
batch_mean, batch_var = tf.nn.moments(x, [0])
else:
batch_mean, batch_var = tf.nn.moments(x, [0, 1, 2])
ema = tf.train.ExponentialMovingAverage(decay=decay)
def mean_var_with_update():
ema_apply_op = ema.apply([batch_mean, batch_var])
with tf.control_dependencies([ema_apply_op]):
return tf.identity(batch_mean), tf.identity(batch_var)
mean, var = tf.cond(is_training, mean_var_with_update,
lambda : (ema.average(batch_mean), ema.average(batch_var)))
return tf.nn.batch_normalization(x, mean, var, beta, gamma, eps)
・畳み込み、全結合処理
バイアス部分を削除して、代わりにbatch_normalizationを行います。
#conv
with tf.name_scope('conv1') as scope:
W_conv1 = weight_variable([5, 5, CHANNEL, 32])
#b_conv1 = bias_variable([32])
#h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_conv1 = conv2d(x_image, W_conv1)
bn1 = batch_norm(h_conv1, is_training)
h_conv1 = tf.n.relu(bn1)
...
#fc1
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([(WIDTH/4)*(HEIGHT*/4)*64, 1024])
#b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, (WIDTH/4)*(HEIGHT/4)*64])
#h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
bn3 = batch_norm(tf.matmul(h_pool2_flat, W_fc1), is_training)
h_fc1 = nn.relu(bn3)
...
is_trainingは学習時かどうかのフラグで、’bool’型のplaceholderを用意して渡しています。
※いろいろなブログを参考に実装してみましたが、いまいちまだBNアルゴリズムの理屈が理解できていないので、壮大に間違っているかもしれないです^^;
結果
4層CNNでbatch_normを使った場合と使わない場合の結果です。
【学習】
入力画像:10クラスのきゅうり画像8000枚(各クラス約800枚)
【テスト】
入力画像:10クラスのきゅうり画像2000枚(各クラス約200枚)
Stepごとに500枚をランダムに選択し入力(ミニバッチ)。それを3000step実施。
<実行環境>
OS:Ubuntu14.04
TensorFlow:0.9.0
CPU:Core i-5@3.2GHz
GPU:なし
batch_normなし
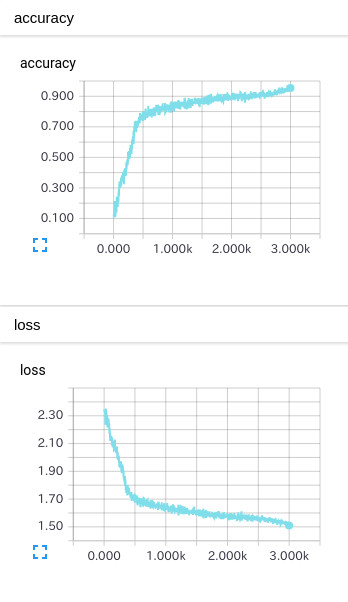
TEST画像に対する正答率:82.9%
完了までの時間:9.3時間
batch_normあり
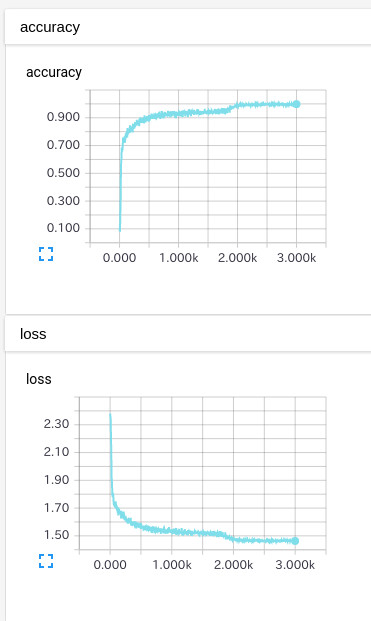
TEST画像に対する正答率:87.2%
完了までの時間:11.7時間
確かに効率良く学習が進んでるようです。
なしの場合だと、3000stepでもまだ入力画像を学習仕切れていないように見えますが、ありの場合だと2000stepぐらいで終わっている感じです。
Lossの収束も全然違いますねΣ(゚∀゚ノ)ノキャー
処理時間はありの方が約1.3倍という結果でした。
これは使った方がいいですね…
あとがき
batch normalizationの理論をいまいち理解しないまま使うのはどうだろう…とか思ってましたが、
結果を見るとこれは使うしか無い!(゚∀゚)アヒャ!
…といった感じです。
さて、きゅうりの学習をさせているわけですが、前回80%だった正答率が87%まで来ました。
もうちょっとで90%を超えそうですが…いろいろ試しているのですが若干手詰まり感がでてきました。
もっとNNを深くしてみたいけど、処理時間が大変なことになりそうです。
実行して終わるのが3日後とか…待てないよ。
このレベルになると多少お金使ってでもクラウドからリソース借りてこようかなとか思いますね。
![[GCP]Cloud Machine Learningを使ってハイパーパラメータチューニング](http://workpiles.com/wordpress/wp-content/uploads/2017/09/hptuning-150x150.jpg)
